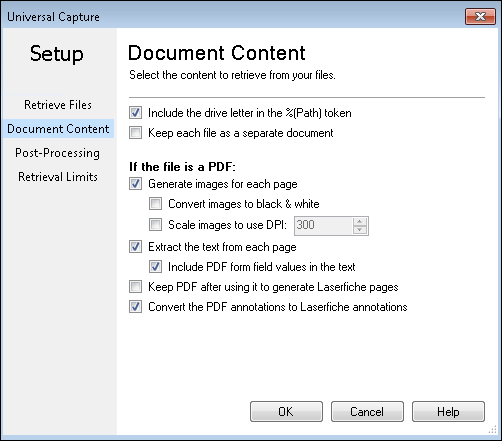
The ![]() Document Content section of the Universal Capture dialog box allows you to define the content you want retrieved from your documents.
Document Content section of the Universal Capture dialog box allows you to define the content you want retrieved from your documents.
For each document:
Example: Mike retrieves images from the following location on his machine: C:\Documents and Settings\Mike\My Documents. If this option is selected, the path token would return C:\Documents and Settings\Mike\My Documents. If this option is not selected, the token would return \Documents and Settings\Mike\My Documents
Note: First Page Identification, Last Page Identification, and document length settings can have an effect on documents even if this option is selected. For more information, see How Documents are Identified.
Example: Jack has a folder on his computer filled with separate purchase order files he wants to process with Quick Fields. He wants each purchase order to remain a separate file, so he selects Keep each file as a separate document.
If the file is a PDF:
Note: The text extracted from PDF form fields will be at the bottom of the Text Pane. If you want their text to be displayed in the Text Pane in their actual location, generate images for each page of the PDF form and OCR it (which will take longer).
Note: If Laserfiche images are generated from PDF forms, the form field values in the PDF forms will be burned into the Laserfiche image.
Note: If Keep each file as a separate document is not selected above, you will not be able to select Keep PDF after using it to generate Laserfiche pages. If the Laserfiche pages in the repository are going to be separated and made into new documents of different lengths, the PDF will not be kept because it cannot be attached to new arbitrary Laserfiche documents. A combination of different file types (doc, pdf, etc) retrieved can be used to create new Laserfiche documents, but the electronic files cannot be kept because of the mixed file types.
Note: Keep PDF after using it to generate Laserfiche pages needs to be selected in order to use Retrieve PDF Form Content.
{kind=link}